.png)
How RunWell Actually Builds AI Automations
A technical deep-dive for the engineers, ops leads, and CTO-types who want to know what's under the hood before signing off on a RunWell engagement.
.png)
If you're the owner of a professional services firm, you can skip this post. Nothing here will help you decide whether RunWell is right for your business — your Blueprint will do that. This post is for the technical person inside the firm. The fractional CTO, the senior dev on retainer, the ops lead who's been burned by an automation vendor before. You're the one who'll get handed our proposal and asked, "Is this legit?" Here's what we actually do, in the level of detail you need to answer that question.
- What "agent-native" means in practice — and why most AI automation agencies aren't.
- Our four-layer architecture: trigger, context assembly, reasoning loop, action and logging.
- How we monitor production automations without ever holding credentials or standing access to your systems.
- The seven questions a technical reviewer should ask in any RunWell discovery call.
The short version
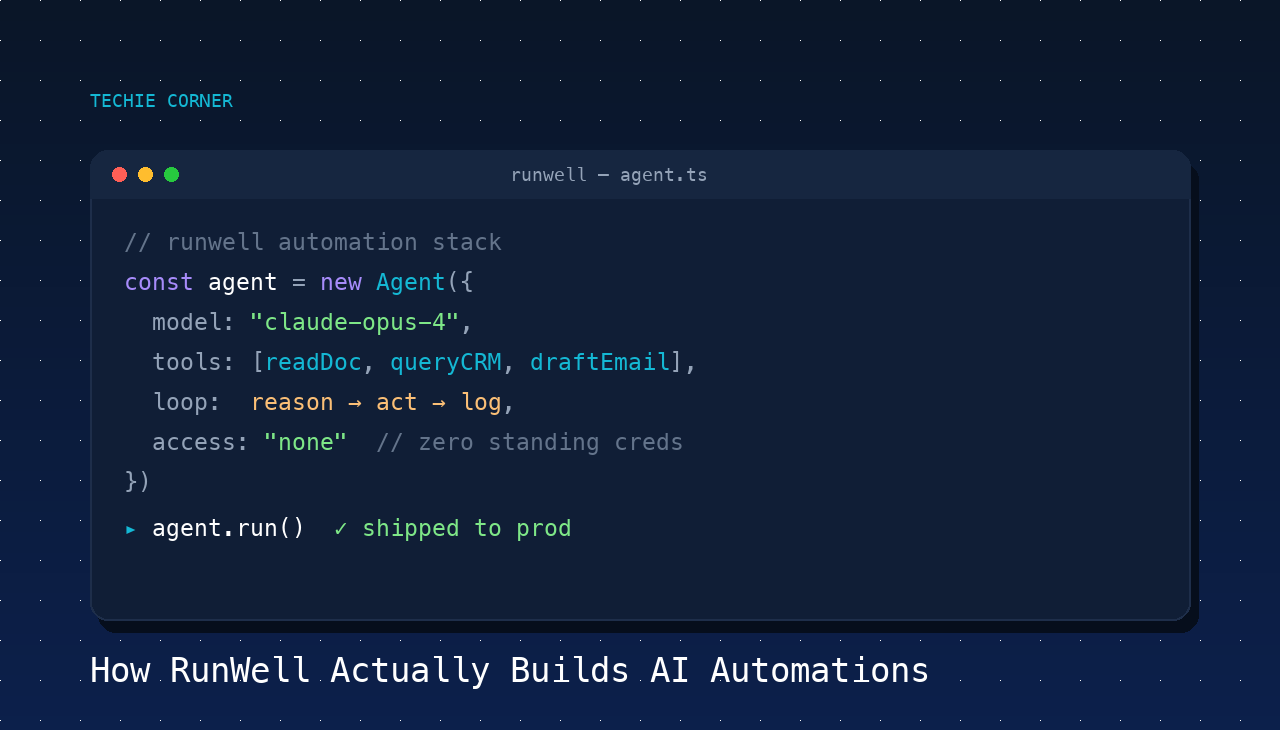
We build agent-native AI systems inside Anthropic's developer environment using Claude Code and Claude Cowork. We do not wrap ChatGPT. We do not move data between SaaS apps with a no-code flowchart and call it AI. We build agents that read documents, reason across tools, follow multi-step workflows, and hand off completed work — the same way a trained junior associate would.
We never take standing access to your systems. We never share credentials. Every automation we build reports its own health back to a RunWell dashboard, which is what we monitor — not your accounts.
If any of those claims need unpacking, read on.
Why most "AI automation" you've seen is garbage
In the last 18 months, every consultant, agency, and Fiverr seller has rebranded as an "AI automation expert." Most of what they ship falls into one of three buckets:
- ChatGPT wrappers. A web form, a system prompt, an OpenAI API call, and an output panel. Useful for FAQ chat. Useless for operational work that needs to read a contract, check a CRM record, and decide whether to escalate.
- No-code flowcharts dressed up as AI. Zapier or Make scenarios with one "AI step" stuffed in the middle that calls GPT to summarize an email. The structural logic is still 100% deterministic if-this-then-that. The AI is decoration.
- Custom GPTs. A glorified search engine over the firm's documents. Helpful as an internal lookup tool. Not automation. Nothing executes.
None of these are wrong as products. They're wrong as solutions to operational waste — because operational waste lives in the multi-step judgment work between the apps. That's the work we build for.
What "agent-native" actually means
An agent-native build is a system where the AI model is making real decisions inside a structured loop, with access to tools that let it act on the world. Concretely, that means:
- The model receives a goal, not a script.
- It has access to a defined set of tools — read this document, query this CRM, draft this email, post to this Slack channel, write to this row in this sheet.
- It chooses which tools to use, in what order, based on what it learns at each step.
- It can ask for human approval at defined gates before taking irreversible actions.
- It logs every decision, every tool call, every input, every output.
This is not novel architecture — it's standard for anyone building seriously with Claude or GPT-4-class models in 2026. What's notable is how few "AI automation agencies" actually build this way. Most are still gluing prompts to Zapier triggers.
We build inside Claude Code (Anthropic's developer-facing agent environment) and Claude Cowork (Anthropic's collaboration-layer agent runtime). These are the same tools Anthropic uses internally. They give us version control, structured tool definitions, observability into every agent decision, and a deployment path that doesn't depend on third-party orchestration platforms going down.
The architecture, concretely
A typical RunWell automation has four layers:
When something breaks, we can replay the exact reasoning trace. When you want to know why an agent made a specific call, we can show you. This is not a black box.
Zero credential sharing. Zero standing access.
This is the part most clients ask about, so let's be specific.
| What other vendors do | What RunWell does |
|---|---|
| Ask for your admin login. Store it. Use it whenever they need to. | Build every integration via the destination system's official API, with a service account or OAuth scope you provision, scoped to exactly what the automation needs. |
| Run a persistent session into your systems 24/7 with broad permissions. Their breach is your breach. | Automations run in our environment, call your API with a narrowly scoped credential, do the work, disconnect. No persistent middleman session. |
| "Trust us" on monitoring. Their dashboard reads from your accounts. | Every automation emits health telemetry — uptime, error rate, latency, cost per run, success rate. We watch the telemetry dashboard. We don't watch your accounts. |
There is no RunWell employee with a password to your CRM. There is no persistent session sitting in a Zapier-style middleman. If something breaks, the dashboard tells us — we don't need to log into your systems to find out. If you've ever had a vendor lose a password and create a security incident, you know why this matters.
Want to see a real reasoning trace from a production agent?
Book a 30-minute technical deep-dive. Redacted for client confidentiality, full architecture walkthrough, your questions. No sales. Just engineering.
Book the technical deep-dive →Why we build in Claude, not GPT or open-source
This question comes up. Honest answer:
Claude's reasoning is better for multi-step operational work
That's not a marketing line — it's been our experience across builds. For document-heavy reasoning (contracts, intake forms, engagement letters, financial documents), Claude makes fewer "lost in the middle" errors and follows multi-turn instructions more reliably. We've A/B tested.
Claude Code and Claude Cowork are first-class agent environments
OpenAI's Assistants API is fine. LangChain and LlamaIndex are fine. But for production agent work with audit trails and structured tool use, the Anthropic stack is what we build for. It's also what Anthropic uses internally, which means the path is well-trodden.
Open-source models are catching up but aren't there yet for this use case
Llama, Mistral, Qwen are improving quickly. When self-hosted reasoning quality matches Claude for multi-step ops work — and clients have a real need for on-prem — we'll build there too. Today, most clients are better served by Claude.
We are not a Claude reseller. We are not financially incentivized by Anthropic. We use Claude because it's the best model for this work today. If that changes, we change.
What we don't do
A short list, because it tells you more than the long version of what we do.
- We don't sell SaaS. There is no RunWell platform you log into. The automations live in your stack.
- We don't lock you in. Every automation we build, you own. Every integration, every prompt, every piece of context engineering — documented and handed over.
- We don't do retainers without earning them. The Engine includes 90 days of guarantee work. After that, the Rails retainer is opt-in and only for clients who've already gone through the Engine.
- We don't take work we can't build. If your stack is too custom or too legacy, we'll tell you in the Blueprint.
- We don't build chatbots. We will not build you "an AI to answer customer questions on your website." That's a different product category and a different vendor.
"We are a builder, not a platform. We ship code into your environment, integrated with your systems, owned by you, monitored by us through telemetry rather than access."
— The RunWell technical thesis, in one sentence
What to ask us in the discovery call
If you're the technical person sitting in on a RunWell discovery call, here are the questions that will tell you whether we know what we're doing.
- 01Show me a reasoning trace from a real production agent.We can. Redacted for client confidentiality.
- 02What's your error rate on production builds, and how do you measure it?Tracked per-automation in the RunWell dashboard. We'll show you the format.
- 03What happens when Claude has an outage?Graceful degradation — automations queue, retry, and alert. We'll walk you through the failure modes.
- 04What does your handoff documentation look like if we want to maintain this internally later?Full prompt library, integration docs, monitoring schema, playbook for adding new automations. Sample available on request.
- 05How do you handle PII?Data minimization at context assembly, no PII in prompt logs by default, optional self-hosted deployment for HIPAA-style needs (priced separately).
- 06What happens at the end of the engagement — who owns what?You own everything that runs in your environment. We hand over the prompt library, the integration code, and the monitoring schema. You can fire us tomorrow and the automations keep running.
- 07Can we run the same automation against a staging environment first?Yes. Every Engine engagement includes a 1–2 week shadow phase against a staging dataset before any production write goes live.
If we can't answer any of these to your satisfaction, don't sign the engagement.
The bottom line for technical reviewers
RunWell is a builder, not a platform. We ship code into your environment, integrated with your systems, owned by you, monitored by us through telemetry rather than access. The AI layer is real Claude reasoning inside a structured agent loop — not a chatbot pretending to do operational work. The architecture is standard for serious 2026 agent development. It's notable mostly because so few people building under the "AI automation" banner are actually doing it this way.
If you have specific technical questions we didn't cover here, book a 30-minute technical deep-dive. No sales. Just engineering.
Questions we get after this article
What happens if Anthropic raises prices or changes terms?
Your automations keep running on whatever model contract you have. We don't markup Anthropic costs - you pay actual usage. If pricing or terms shift in a way that breaks your unit economics, we help you migrate to whichever frontier model makes sense at that point.
Can we host the agents in our own infrastructure instead of yours?
Yes - for clients with HIPAA, FINRA, or specific data residency requirements. Self-hosted deployment is priced separately on the Engine. The architecture is the same; only the runtime location changes.
What does the engagement timeline actually look like?
Blueprint: 48-72 hours after intake. Architect: 30 days for one automation. Engine: 6 weeks for five automations, with the first one live in 72 hours. We work in 2-week sprints with weekly demos so you see progress the entire way.
How is this different from hiring a Zapier consultant or a no-code agency?
A Zapier consultant connects apps. We build agents. Different work, different cost, different outcomes. If your problem is "move data from app A to app B," hire a Zapier consultant. If your problem is "the work between the apps is what's killing us," that's what we build for.
What if we already use a different AI provider (OpenAI, Azure, AWS Bedrock)?
We can build against any frontier model with a tool-use API. We default to Claude because the reasoning quality is better for multi-step ops work, but if you have an existing Azure or Bedrock contract for compliance reasons, we'll build there. Architecture stays the same.
Do you actually do the engineering, or do you outsource it?
Felicia builds every Engine engagement personally. No offshore subcontractors, no white-labeled junior dev shop. The whole point is that the same person who diagnoses the leak is the person who builds the fix.

Want to see your firm's number?
10 questions. 3 minutes. A score out of 100 plus your top 3 operational gaps, with a dollar figure attached. Free. No email required to see the result.
Disclaimer. This article is for educational purposes only and does not constitute legal, accounting, tax, medical, or financial advice. References to specific compliance frameworks (ABA Model Rules, AICPA SSTS, HIPAA, SEC/FINRA, state bar rules) reflect the authors' and reviewers' interpretation as of the publish date and may not apply to your jurisdiction or specific facts. Consult your own licensed advisor before acting on anything written here. Statistics and case details have been anonymized; dollar figures reflect actual client outcomes as of the engagement date. RunWell is not a law firm, CPA firm, or registered investment advisor.